
مدیریت زنجیره تأمین نامشخص
تخمین ماتریس حمل و نقل بار (مبدا-مقصد) بین شهری با استفاده از الگوریتم شبیه سازی تبرید
محسن صادقی و غلامعلی شفابخش
چکیده:
اطلاعات تقاضای سفر به عنوان ماتریس مبدا-مقصد (O-D) حمل و نقل نقش مهمی در مهندسی و برنامه ریزی حمل و نقل بین شهری ایفا می کند. دسترسی به این ماتریس از روشهای متداول نیاز به صرف زمان ، پول و منابع انسانی دارد. در طی سالهای اخیر ، مطالعات بسیاری برای بدست آوردن ماتریس O-D باری با استفاده از اطلاعات شمارش وسیله نقلیه بار در لینک های شبکه انجام شده است. علاوه بر این ، تخمین ماتریس O-D و برقراری ارتباط آن با وسایل نقلیه حمل و نقل می تواند به برنامه ریزان کمک کند تا مشکلات لجستیک ، ایمنی و نگهداری را بهبود ببخشند. در این مقاله روشی مبتنی بر به حداقل رساندن انحرافات بین مقادیر مشاهده شده و تخمین زده شده برای یافتن ماتریس O-D باربری ارائه شده است. برای حل مدل ، از داده های شمارش ترافیک کامیون ها در لینک های شبکه و همچنین سایر منابع اطلاعاتی مرتبط استفاده می شود. این مدل برای یک مطالعه موردی در ایران با استفاده از الگوریتم تبرید شبیه سازی فرا ابتکاری حل شده است.
- مقدمه
در طی دو دهه گذشته ، برآورد ماتریس O-D یا جدول سفر بر اساس اطلاعات موجود به طور فزاینده ای در حوزه تحقیقات مورد توجه بوده است. ماتریس O-D یک ورودی اساسی برای برنامه ریزی حمل و نقل است. عناصر این ماتریس تعداد سفرهای بین مناطق مختلف در سراسر یک شهر ، استان یا کشور را در طی یک بازه زمانی معین نشان می دهد. هزینه های بالای تولید چنین ماتریس هایی از روش های مستقیم و بررسی باعث شده است که بسیاری از محققان از روش های دیگر استفاده کنند. اختصاص ماتریس O-D به شبکه حمل و نقل منجر به ترافیک در لینک های شبکه می شود ، در حالی که ماتریس O-D را می توان از تعداد ترافیک در لینک های شبکه بدست آورد و در واقع یک عمل معکوس انجام می شود. در دهه های اخیر رویکردهای بی شماری برای تخمین ماتریس OD اعمال شده است (وانگ و همکاران ، 2016) و بیشتر آنها مستقیماً از شمارش لینک ترافیک استفاده می کنند. روشهای متداول شامل روش به حداکثر رساندن آنتروپی (Van Zuylen & Willumsen, 1980) ، برآورد حداکثر احتمال (Spiess، 1987)، تخمین ماتریس O-D
(Cascetta & Nguyen, 1988), ، حداقل مربعات عمومی (GLS) (Bell, 1991) و تکنیک های ارزیابی استنتاج (Maher, 1983)..
با توجه به اینکه بیشتر تحقیقات در این زمینه بر اساس سفرهای شهری و مسافری صورت گرفته است ، روشی در این مطالعه برای ماتریس حمل و نقل O-D برای یک کشور ارائه شده است. هدف از این مطالعه تخمین ماتریس OD باری برای دوره های مختلف (ماهانه ، چند ماه یا سالانه) با استفاده از یک مدل است که در آن ورودی ها شامل شمارش وسایل نقلیه تجاری باری در لینک های شبکه و اطلاعات اولیه بدست آمده از بررسی های میدانی در دوره های مختلف در ایران است. . این مدل با استفاده از الگوریتم شبیه سازی تبرید حل شده و سعی می شود از منابع مختلفی برای تخمین بهتر ماتریس O-D باری استفاده شود.
پس از بررسی مطالعات قبلی ، اهداف این تحقیق نیز مشخص می شود و مدل تخمین ماتریس O-D ارائه می شود. این مدل مبتنی بر به حداقل رساندن انحراف بین مقادیر مشاهده شده و تخمین زده شده ، در بسیاری از مطالعات برآورد ماتریس O-D به کار رفته است. همچنین در این مقاله با اعمال تغییراتی در مدل و به ویژه تبدیل پارامترهای آن به پارامترهای مرتبط با حمل بار و ایجاد آن در بین شهری کردن آن مورد استفاده قرار گرفته است. کوهن (1995) برای توسعه مدل حمل و نقل بار ، که داده های اولیه و ثانویه بودند ، دو سری داده را به کار برد. داده های اولیه شامل تعداد ترافیک شبکه و داده های ثانویه شامل بررسی های دوره ای می باشد.
به همین دلیل ، در این مقاله ، اطلاعات شبکه حمل و نقل جاده ای ایران ، موقعیت مکانی و داده های شمارنده ترافیک به عنوان داده های اصلی در نظر گرفته شده است. علاوه بر این ، برخی از ضرایب مانند کامیون های خالی بین هر جفت O-D و میانگین بار هر کامیون 2 محور ، 3 محوره و بیشتر برای هر جفت O-D به عنوان داده های ثانویه در نظر گرفته می شوند. این داده ها از نظرسنجی های انجام شده برای ارائه تخمین مطلوب ماتریس O-D بدست آمده است. بخش پایانی همچنین خلاصه ای از تلاشها و توصیه های تحقیقاتی برای تحقیقات آینده را ارائه می دهد.
- مروری بر تحقیقات پیشین
اگرچه بسیاری از تلاش ها در مدلهای تخمین ماتریس O-D روی وسایل نقلیه مسافری متمرکز بوده است ، از اوایل دهه 1990 ، برآورد ماتریس O-D از کامیون ها توجه بسیاری را به خود جلب کرده است. روش های تخمین ماتریس O-D با وسایل نقلیه حمل و نقل بار در ارتباط است و کامیون ها تقریباً در ساختار با روش های تخمین مسافر یکسان هستند. مطالعات زیادی در رابطه با برآورد ماتریس مبدا-مقصد باری یا تعیین جدول حرکت کامیون ها بین مبدا- مقصد انجام شده است. از آنجا که تخمین ماتریس OD از بار کاملاً متفاوت از ماتریس مبداء مقصد مسافر است ، در اکثر مطالعات علاوه بر استفاده از داده های مرتبط با تعداد ترافیک ، از بانک اطلاعاتی دیگری نیز استفاده می شود (به عنوان مثال شعبانی و فیگلیوززی ، 2012) . برای تعیین برخی از نکات از قبیل تشخیص رفتار کامیون های خالی و میانگین ضریب اشغال بار از نوع هر کامیون ، باید از اطلاعات پایگاه داده و همچنین بررسی های مرتبط استفاده شود. در این مدلها ، هدف برآورد ماتریس O-D است که جریانهایی را با داده های واقعی و مشاهده شده سازگارتر می کند. تامین و ویلومسن (1989) از یک مدل سه مرحله ای برای برآورد تقاضای جریان حمل و نقل بر اساس اجرای مدل های جاذبه و حداقل مربعات استفاده کردند.
کراینیک و همکاران. (2001) برای تنظیم ماتریس تقاضای حمل و نقل هدف از یک برنامه دو سطحی استفاده کردند. سطح بالای آن برای به حداقل رساندن تفاوت بین تعداد کامیون های مشاهده شده و برآورد شده و سطح پایین مدل تخمین ترافیک به عنوان روش بهینه سازی سیستم در نظر گرفته شده است. چنین داده هایی شامل هر نوع ترکیبی از تعداد ترافیک لینک های انتخاب شده ، ماتریس O-D سایر دوره های زمانی ، بسته به هر منطقه و شروع و پایان سفر بسته به هر منطقه و شمارش خطوط تقاطع می باشد. (لیست و همکاران ، 2002). لیست و ترانکویسیت 1994 اولین تحقیق را با استفاده از چنین روش هایی برای تخمین ماتریس O-D حرکت کامیون ها انجام داد. آنها روشی را برای برآورد ماتریسهای سفر کامیون در چند کلاس بر اساس مشاهدات حجم ترافیک و برخی اطلاعات دیگر ارائه دادند. مجموعه داده های دارای ویژگی های مختلف متفاوت با روشی کارآمد و مؤثر ترکیب می شوند به طوری که هر قطعه اطلاعات در توسعه جریانهای تخمینی نقش دارد. مدل List و ) Turquist 1994) با برآورد ماتریس های سفر به عنوان یک مسئله به حداقل رساندن خطی در مقیاس بزرگ پرداخته و هدف این بود که تمام انحرافات مقادیر برآورد شده از مقادیر مشاهده شده را به حداقل برساند. این مدل بیشترین استفاده ممکن را از اطلاعات موجود فراهم می کند. مطابق تحقیقات List و Turnquist ( 1994 ) ، رئوس و همكاران. (2002) اهمیت طبقه بندی اطلاعات مختلف را در تخمین ماتریس O-D بار ارزیابی کرد. با توجه به این مطالعه ، نتیجه گیری شد که ، داده های شمارش ترافیک از لینک می توانند مفیدترین بخش اطلاعات تلقی شوند و از آن زمان ، آمار تولید سفر مبدا و جذب سفر مقصد به صورت کل جمع می شود. لیست و همکاران (2002) مدلی را برای برآورد جریان کامیون ها برای منطقه نیویورک ارائه داد. اگرچه این مدل بر اساس کار List و Turquist ( 1994) شکل گرفته است ، اما با افزودن انواع جدیدی از مشاهدات به مجموعه های قبلی مشاهدات ، پیشرفت هایی نسبت به مدل قبلی داشته است. ژانگ و همکاران (2004) با استفاده از داده های CFS و داده های TRANSEARCH جریان چند وجهی شامل جاده ، ریلی و رودخانه ای داخلی را برای ایالت می سی سی پی بدست آورد. Al-Battaineh و Kaysi ( 2005) همچنین از الگوریتم ژنتیکی برای یک مسئله بهینه سازی استفاده کردند که در آن تابع هدف به حداقل رساندن حداقل مربعات بین مشاهدات و داده های برآورد شده برای برآورد ماتریس OD باربری بود. جانسووان و همكاران (2016) یک روش دو مرحله ای برای برآورد جدول سفر کامیون ها ارائه داد. در حقیقت ، آنها از جریان باری و داده های مربوط به شمارش حجم کامیون ها استفاده می کردند. در مرحله اول جدول سفر مبدأ – مقصد مبدل به مقصد از طریق پایگاه داده جریان حمل و نقل برآورد شد. سپس در مرحله دوم جدول سفر کامیون ها با استفاده از برآوردگر جریان مسیر اصلاح شد تا با شمارش حجم کامیون ها بهترین تطابق را بدست آورند. آنها تخمین را در مورد ایالت UTAH انجام داده و از پایگاه داده های FAF و USTM استفاده کردند. در ادبیات تحقیق خود همچنین به این نکته اشاره کردند که ، اساساً ، مدل های تخمین ، ماتریس مبداء حمل و نقل – مبنای سفر یا مبنای حمل و نقل بوده است.
اگرچه امروزه داده های بیشتری برای تخمین ماتریس مبدا-مقصد حمل و نقل به خصوص در کشورهای توسعه یافته مانند داده های GPS در کامیون ها مورد استفاده قرار می گیرد. داده های GPS موقعیت کامیون ها را در مناطق مختلف نشان می دهد. با این حال ، آنها قادر به ایجاد فاکتور اشغال بار نیستند ، یا می توانند مشخص کنند که آیا کامیون ها خالی هستند یا خیر و یا برخی نکات دیگر. ma و همکاران (2011) ، پیناری و همکاران. (2013) و Flaskou و همکاران. (2015) از جمله محققانی بود که برخی از مطالعات را برای تولید جریان بار انجام داد. اما به دلیل کمبود چنین داده هایی در ایران و نبود GPS در کامیون ها ، استفاده از چنین مدل هایی امکان پذیر نیست.
این مقاله با استفاده از تکنیک های مدل سازی با استفاده از تعداد ترافیک کامیون ها و وسایل نقلیه تجاری شکل گرفته است تا بتواند مدل سازی حمل و نقل بار را در یک منطقه بزرگ بهبود بیشتری بخشد. با استفاده از ماتریس O-D تخمین زده شده به ماتریس مشاهده شده در مقیاس بزرگ ، به عنوان بخشی از عملکرد هدف یک مسئله به حداقل رساندن در این مطالعه در نظر گرفته شده است. داده های مربوط به حمل و نقل بار در ایران تا حد امکان مورد استفاده قرار گرفت و در نهایت این مدل برای شبکه حمل و نقل ایران استفاده شد.
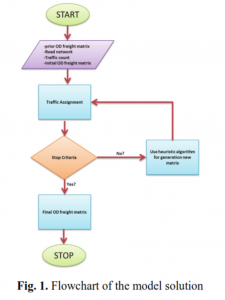
- روش تحقیق
روش های مختلفی برای برآورد ماتریس O-D از حجم ترافیک لینک های شبکه ارائه شده است. نمونه های این روشها شامل روش حداکثر احتمال (Spiess ، 1987) ، حداقل مربعات عمومی (Cascetta ، 1984) و تکنیک های تخمین استنباطی است (Maher، 1983). همه این روشها هدف یکسانی را دارند که به حداقل رساندن خطای بین مقادیر مشاهده شده و مقادیر برآورد شده از مدل است.
تفاوت اصلی تخمین ماتریس حمل و نقل بار و مسافر در این مدلها در این است که در برآورد ماتریس مبدا-مقصد مسافر در واقع هیچ وسیله نقلیه خالی وجود ندارد و راننده به عنوان مسافر در نظر گرفته می شود. با این حال ، در تخمین ماتریس مبدا-مقصد باری ، ابتدا ، شمارش تعداد انواع کامیون ها مهم است. دوم ، ضریب اشغال بار برای هر نوع کامیون (انواع مختلف کامیون هایی که شمارش می شوند) و در آخر ، نسبت کامیون های خالی به کل کامیون های عبوری از هر نوع از اهمیت ویژه ای برخوردار است.
به عنوان مثال ، در کالیفرنیا در ایالات متحده و در سرشماری ترافیک ، داده های ترافیکی به خصوص برای کامیون ها بر اساس تعداد محورهای آنها شامل کامیون هایی با 2 ، 3 ، 4 و 5 محور و بیشتر موجود است ، این در حالی که چنین چیزی مربوط به وسایل نقلیه مسافری وجود ندارد. این در حالی است که در ایران همین داده ها فقط برای کامیون هایی با محور 2 ، 3 و بیشتر ثبت شده است. بنابراین ، مجموع این امتیازات تفاوت بین حل مشکل برای برآورد ماتریس های مسافری و کامیون بار را نشان می دهد.
در سایر مقالات ارائه شده در این زمینه ، از ماتریس O-D مشاهده شده ، تخمین زده شده شهری و شمارش ترافیک وسایل نقلیه تجاری حمل بار استفاده شده است. در ایران حجم ترافیک در نقاطی که شمارش ترافیک به صورت مکانیزه انجام می شود و با استفاده از شناسه های راهنمایی و رانندگی کاملاً تفکیک شده و در دسته خودروهای حمل بار ، وسایل نقلیه به دو دسته تقسیم می شوند: کامیون های 2 محوره ، کامیون های 3 محوره. و کامیون های با محور بیشتر. علاوه بر این ، عوامل کامیون های خالی و متوسط بار برای انواع کامیون ها بین هر جفت O-D در دو بازه زمانی با بررسی میدانی بدست می آید. پارامترهای دیگری که توضیحات آنها در زیر ارائه شده است از روش های محاسباتی و مشخصات فنی و ترافیکی بدست می آیند. سهم مشخصات فنی ترافیکی هر جفت O-D از هر لینک در میان آنها قرار دارد. بنابراین در این مطالعه سعی شده است از تمام اطلاعات موجود استفاده شود. علاوه بر این ، از همه یا هیچ چیز مدل واگذاری برای مشخصات فنی ترافیک استفاده شده است. دلیل این موضوع عدم وجود مسیرهای متعدد بین مبدا و مقصد است. برخلاف مسیرهای پر ازدحام و شلوغ شهری ، در شبکه راه شهری ، کاربران به دلیل عدم شلوغی ترجیح می دهند از کوتاهترین مسیر استفاده کنند. در این مقاله از الگوریتم شبیه سازی تبرید به عنوان روشی برای تعیین پاسخ مطلوب و بهینه در مسئله به حداقل رساندن استفاده شده است. سرانجام ، این مسئله می تواند به شرح زیر تنظیم شود ،
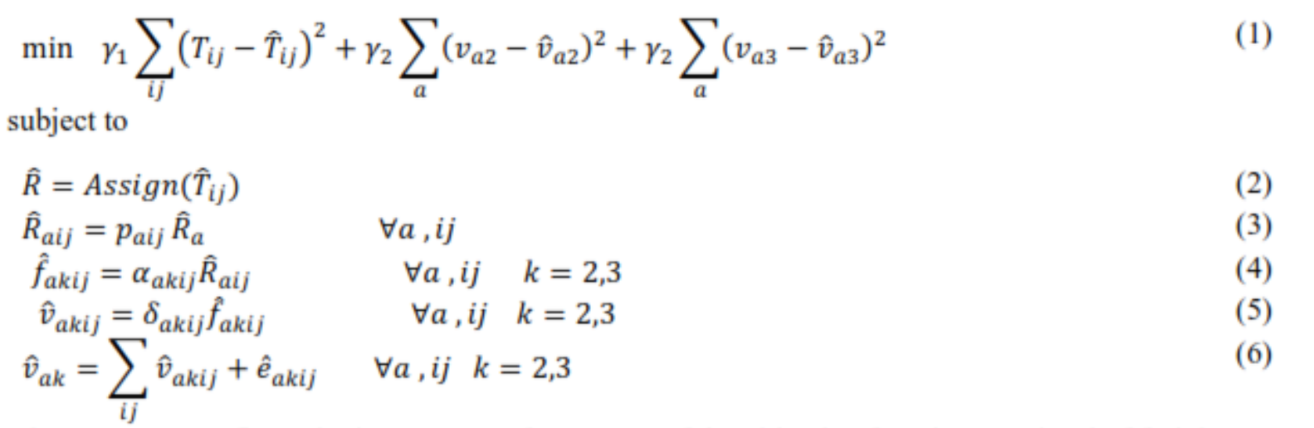
که در آن ، γ1 & γ2 اهمیت دو بخش از تابع هدف شامل ماتریس O-D و تعداد ترافیک را نشان می دهد . ماتریس حمل و نقل O-D اولیه ، ماتریس حمل و نقل تخمین زده شده ، بردار حمل بدست آمده از واگذاری ماتریس به لینک ها شبکه، حجم بار در لینک a می باشد. سهم O-D از جفت i,i از لینک عبور حجم جریان از لینک a است. مقدار حجم باری است که بین جفت O-D ij در لینک a جریان می یابد. تعداد کامیون های 3 محوره شمارش شده در لینک a ، تعداد کامیون های 3 محوره و بیشتر شمارش شده در لینک a. تعداد کامیون های 2 محوره محاسباتی (از طریق تعیین ماتریس ) و تعداد کامیون های 3 محوره و بیشتر (از طریق تعیین ماتریس ) در لینک a . اختصاص تابع واگذاری بار به شبکه است. شاخص k مربوط به نوع کامیون (2-محور یا 3 محور و بیشتر) است. بار حمل شده توسط نوع کامیون k در لینک a بین جفت O-D ij است. عامل مقدار بار فعلی را در لینک بین دو نوع وسیله نقلیه تقسیم می کند.
ضریب از بانک اطلاعاتی وزن سیستم های حرکتی و همچنین وزن سنتی برای 212 لینک بدست می آید. برای به دست آوردن ضریب برای سایر پیوندهای شبکه و برای هر جفت مبدأ – مقصد ، از میانگین ارزش کمان ها استفاده می شود که از روش های آماری بدست آمده است. بنابراین ، مسیرهای فعال هر جفت مبداء مقصد و پیوندهای آن مشخص شده و ضریب میانگین برای کل پیوندهایی که هیچ داده ای در دسترس نیست استفاده شده است. تعداد کامیون های کامل از نوع k در لینک a بین جفت مبداء مقصد ij است. ضریب تبدیل بار به کامیون برای کامیون های نوع k ، بین جفت مبداء مقصد ij است. این ضریب نیز مانند نمونه قبلی و از همان پایگاه داده بدست می آید. علاوه بر این ، از همان داده ها برای پیوندهایی که داده های آن در دسترس است استفاده شده است. و برای سایر پیوندها به همان روش روش قبلی محاسبه شده است. سرانجام ، تعداد کامیون های خالی از نوع k در لینک k بین جفت مبداء مقصد ij است که از همان بانک اطلاعاتی بدست می آید و نسبت کامیون های کامل از نوع k در هر لینک است. ضریب به طور مستقیم برای پیوندهایی که دارای سیستمهای حرکتی هستند و برای سایر پیوندها می توان از طریق روش فوق محاسبه کرد.
4- روش حل
هدف از این مطالعه ، بهبود مدل سازی حمل و نقل کالا در سراسر کشور از طریق روشی مبتنی بر شمارش ترافیک وسایل نقلیه تجاری و کامیون های موجود در لینک های شبکه با استفاده از الگوریتم شبیه سازی تبرید به عنوان موتور بهینه سازی است. الگوریتم شبیه سازی تبرید یک الگوریتم بهینه سازی ساده ، مؤثر و فرا ابتکاری برای حل مسائل بهینه سازی است. این روش با استفاده از روش بهینه سازی مونت کارلو ارائه شده توسط متروپولیس و همکاران (1953) ، کرکپاتریک و همکاران در(1983 ، 1985) برای حل یک مشکل پیچیده بهینه سازی ترکیبی از الگوریتم شبیه سازی تبرید استفاده کرد. از آن زمان برای حل مشکلات مختلف از جمله متغیرهای مستقل از روش شبیه سازی تبرید استفاده شده است. از جمله مشکلات مرتبط با تحقیقات حمل و نقل که با استفاده از الگوریتم شبیه سازی تبرید حل شده است ، مشکل فروشنده دوره گرد (Cerny ، 1985) ، مشکل مسیریابی وسایل نقلیه (Woch & Lebkowski ، 2009) ، برنامه ریزی ترانزیت (Poorjafari & Holyoak ، 2014) و طراحی شبکه (Jayaraman & Ross ، 2003).
تکنیک تیبرید تدریجی در متالوژی برای دستیابی به وضعیتی که ماده جامد به خوبی مرتب شده و انرژی آن به حداقل برسد استفاده می کند. این روش شامل قرار دادن مواد در دماهای بالا و سپس کاهش تدریجی دما است. برخلاف روش های بهینه سازی مکانی که فقط می توانند حداقل مقدار نسبت به پاسخ حدس زده اولیه را پیدا کنند ، روش شبیه سازی تبرید می تواند حداقل مقدار مطلق را پیدا کند. مفهوم اصلی روش شبیه سازی تبرید از فرآیند فیزیکی تبرید فلزات مذاب سرچشمه گرفته است. در فرآیند تبرید ، یک فلز مذاب به تدریج در دماهای بسیار بالا سرد می شود. اتم های فلزی به طور تصادفی در دمای بالا قرار می گیرند و بنابراین به راحتی می توانند به سمت یکدیگر منتقل شوند. با کاهش تدریجی دما ، حرکت اتم ها محدود است به طوری که اتم ها شروع به مرتب سازی و تشکیل کریستال می کنند. سطح انرژی کریستال شکل گرفته به سرعت خنک کننده فلز بستگی دارد. اگر کاهش دما به سرعت انجام شود ، ممکن است ساختار بلوری شکل نگیرد و در عوض یک ساختار غیر کریستالی با سطح انرژی بالا تشکیل شود. از این رو برای رسیدن به کمترین سطح انرژی ، فرایند خنک کننده باید به آرامی انجام شود.
روش شبیه سازی تبرید با استفاده از شبیه سازی فرایندی که در بالا ذکر شد ، مقدار مطلق یک تابع هدف را می یابد. عملکرد هدف معادل سطح انرژی است که باید با استفاده از یک سری تغییرات بهینه ساز به حداقل برسد. در این روش ، فرآیند خنک کننده بر اساس عملکرد توزیع بولتزمن با کنترل یک پارامتر دمای شبه شبیه سازی می شود. کاهش آهسته دما معادل پذیرش تغییرات دمای غیر بهینه ساز با احتمال خاصی است که با کاهش مقدار عملکرد هدف کاهش می یابد. روش شبیه سازی تبرید از توزیع بولتزمن همانطور که در عبارت 7 نشان داده شده است استفاده می کند. به صورتی که که ، E و T به ترتیب انرژی و دمای سیستم را نشان می دهند. همچنین نمایانگر ثابت بولتزمن است. این توزیع ادعا می کند که وقتی یک سیستم در دمای T در تعادل حرارتی قرار دارد ، توزیع انرژی دارد که بین همه حالت های مختلف انرژی توزیع می شود. همیشه این احتمال وجود دارد که حتی در دمای پایین دمای انرژی سیستم زیاد باشد. بنابراین ، این احتمال وجود دارد که سیستم از حداقل انرژی محلی خارج شود و به یک مقدار مطلق همگرا شود.

الگوریتم راه حل در شکل 2 نشان داده شده است.

بگذارید ماتریس O-D اولیه بار برای یک سال خاص باشد ، مجموعه ای از حجم ترافیک در لینک های شبکه برای کامیون های 2 محوره ، 3 محوره و بیشتر که با و نیز مشخص شده اند ، برای همان سال برای همه استخراج شده اند نقاط با تعداد ترافیک حال لازم است که پاسخ اولیه را برای ماتریس دنبال کنید. به همین دلیل ، عناصر ماتریس به طور تصادفی تغییر می کنند تا یک ماتریس جدید مانند ایجاد شود. روش کار این است که هر عنصر ماتریس بطور تصادفی به گونه ای تغییر یافته است که عنصر مربوطه آن در ماتریس دارای حداکثر درصد افزایش β یا درصد کاهش β ،
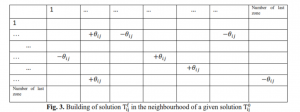
اکنون یک ماتریس خراب شده بدست می آید که در آن هر عنصر از آن به طور تصادفی تا β درصد از نسبت بالا و پایین نسبت به ماتریس تغییر می یابد. این ماتریس به عنوان پاسخ اولیه استفاده خواهد شد. برای تغییر پاسخ و ایجاد پاسخ جدید ، با نمایه سازی عناصر ماتریس از 1 به مربع عدد منطقه ، 4 عنصر در بین عناصر کاهش یافته و 4 عنصر از بین عناصری انتخاب می شوند که بطور تصادفی افزایش یافته اند. سپس ، این 8 عنصر مطابق با معادلات زیر اصلاح خواهند شد:
(9)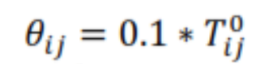
(10) برای عناصری که نسبت به ماتریس اولیه افزایش یافته است 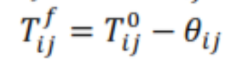
(11) برای عناصری که نسبت به ماتریس اولیه کاهش یافته است 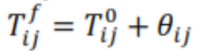
مجدداً تعداد ردیف ها و ستون های ماتریس که تغییر نکرده اند باید به مقدار اولیه برگردانند تا زمانی که تغییری در جمع ردیف ها و ستون های ماتریس نسبت به ماتریس اولیه ایجاد نشود. مقدار درجه حرارت اولیه و نهایی باید با توجه به ساختار مشکل تعیین شود ، به طوری که احتمال پذیرش پاسخ بد در ابتدای تکرارهای الگوریتم باید زیاد باشد و در پایان باید بسیار کم باشد. بنابراین ، مقدار تابع هدف برای اولین بار محاسبه و سپس درجه حرارت با توجه به شرایط فوق در نظر گرفته شد. به عنوان یک نتیجه ، درجه حرارت اولیه به 0.1 و مقدار L ، 100 بود. برای کاهش دما ، از عملکرد نمایی توصیف شده در الگوریتم با r = 0.95 و کاهش 1000 بار در دما استفاده می شود.
- مطالعه موردی در ایران
مدل پیشنهادی برای شبکه راه ایران با طول 34600 کیلومتر و همچنین 56 منطقه ترافیکی اجرا شده است. با توجه به انجام شمارش ترافیک برای 1165 بخش در شبکه مذکور و تعداد مشخصی از کامیون های 2 محوره ، 3 محوره و بیشتر در هر یک از این نقاط ، از این داده ها به عنوان داده ورودی استفاده شده است. در این مقاله از داده های شمارش ترافیک در ایران استفاده شده است ، اگرچه می توان تعداد گره ها را به عنوان یک مشکل فرعی مطرح کرد. خان و اندرسون (2016) محدودیت تعداد لینک های شمارش ترافیک را در دقت تخمین زده شده ماتریس O-D بررسی کردند. علاوه بر این ، از ماتریس باری O-D که از نظرسنجی میدانی وزارت راه و شهرسازی در سال 2011 بدست آمده استفاده شده است.
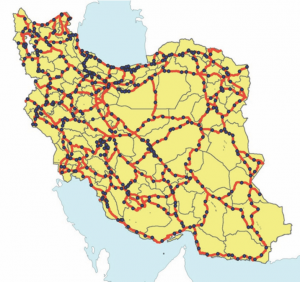
شکل 4. جاده های شریانی ایران و مکان های شمارش ترافیک.
5.1. ورودی های مدل
مدل پیش بینی شده به جریان واقعی لینک به عنوان ورودی نیاز دارد که باید در عملکرد هدف قرار گیرد. از آنجا که این روش به ماتریس O-D باری به عنوان جریان وسیله نقلیه مربوط می شود ، باید این جریان از پیوندها به عنوان تعداد کامیون (2-محور و 3 محور و بیشتر) به مدل وارد شود. این داده های آنلاین در 1165 نقطه در ایران گرفته شده است. شکل 4 مکان شمارش ترافیک را نشان می دهد. از طرف دیگر ، این مدل به یک ماتریس باربری O-D اولیه نیاز دارد. این ماتریس همچنین با مطالعات میدانی در سال 2011 بدست آمد
5.2 منطقه بندی
اولین قدم برای هرگونه فعالیت برنامه ریزی حمل و نقل ، منطقه بندی است. از آنجا که هیچ قاعده خاصی در این زمینه وجود ندارد ، بسیاری از محققان روش های مختلفی را مورد توجه قرار داده اند (مارتینز و همکاران ، 2007). در این مقاله ابتدا مناطق تولید و جذب باری که در آن فعالیت های اقتصادی انجام می شود باعث تولید و جذب ترافیک باری از / به سایر مناطق مورد مطالعه شده است. هر منطقه باید دارای مرکزی باشد که «مرکز ثقل» فعالیت های اقتصادی باشد و همه جابجایی ها از / به منطقه می توانند در آنجا اندازه گیری شوند. بنابراین ، ملاحظات و معیارهای زیر برای تعریف مناطق مورد استفاده قرار گرفته است. سیستم مناطق باید با تقسیمات کشور متناسب باشد ، خصوصاً در آمار مربوط به جمعیت و تولید. بنابراین ، از این منظر ، مناطق را می توان تعریف کرد: یک سری واحدهای کوچکتر که می توانند در مطالعات مختلف به روش های مختلف جمع شوند تا نتایج این مطالعات بتواند با یکدیگر سازگار و قابل مقایسه باشد. مناطق باید تا حد امکان یکدست باشند. این امر در مورد مناطق شهری صدق می کند زیرا بر اساس اصل همگن بودن مناطق تعریف شده یا اهداف سفر ، مناطق کوچکتر هستند. این موضوع در مناطق شهری آسان است زیرا این مناطق کوچکتر هستند و براساس اصل همگن مناطق یا اهداف سفر تعریف می شوند. این در مطالعات بین شهری تا حدودی دشوارتر است زیرا مناطق بزرگتر هستند و هر یک نیز شامل امکانات متنوعی یا ساکنین مختلف است. از این رو ، یکدست بودن باید براساس اهداف مطالعه و 2 متغیر اندازه منطقه و واحدهای تقسیمات کشوری متعادل شود. برای تعیین مرز مناطق ، از جاده های اصلی نباید استفاده شود و مبدا سفر و مقصد نباید در مرز مناطق باشد ، زیرا این مسئله در فرآیند مدل سازی مشکلی برای تعیین ترافیک ایجاد می کند. مناطق باید منعکس کننده حوزه عادی نفوذ مرکزیت آن و همچنین شبکه های داخلی منطقه باشند. این نیز باید در ظاهر منطقه به گونه ای قابل مشاهده باشد که خصوصیات داخلی منطقه را نیز نشان دهد. مناطق لزوماً نباید به یک اندازه باشند ، اما اندازه آنها باید متناسب با واحدهای زمان سفر باشد. بنابراین مناطق پر ازدحام باید ابعاد کمتری داشته باشند. چانگ و همکاران (2002) بر اهمیت این موضوع در تخمین ماتریس O-D تأکید کرد. هر منطقه با یک نقطه تعادل یا مرکز ثقل مشخص می شود. در مطالعات شهری ، مراکز ثقل نقاط مجازی هستند که میانگین هزینه سفر به هر جای دیگر منطقه را نشان می دهد.

شکل 5. منطقه بندی ایران
این نقاط معمولاً به یک سایت خاص وابسته هستند ، اما لزوماً اینگونه نیست. این نقاط با استفاده از یک لینک (لینک مجازی) به شبکه وصل می شوند که بیانگر هزینه متوسط اتصال به یک گره در شبکه واقعی (جاده) است. در مطالعات بین شهری که از مناطق بزرگتر استفاده می شود ، برعکس این روند. بدین معنی که ابتدا نقطه مرکزی که نماینده مراکز تولید و جذب است تعیین می شود. سپس مرز منطقه بر اساس حوزه نفوذ در نقاط مرکزی مناطق مجاور تعریف و تعیین می شود. سرانجام ، ایران پس از جمع آوری اطلاعات و تقسیمات لازم به 56 منطقه تقسیم می شود در حالی که 31 استان در ایران وجود دارد. از طرف دیگر ، در مطالعات انجام شده توسط لیم و همکاران. (2014) اشاره شده است که کشوری مانند ایالات متحده آمریکا برای تجزیه و تحلیل حمل و نقل کالا می تواند به 114 منطقه تقسیم شود. این نشان می دهد که با در نظر گرفتن حجم بار داخلی در هر دو کشور و مناطق آنها ، 56 منطقه با توجه به محدودیت داده های موجود برای ایران مناسب است. سرانجام ، پهنه بندی ایران به شکل 5 نشان داده شده است.
5.3 نتایج
برای حل مدل (1) علاوه بر پردازش داده های ورودی ، مقادیر و نیز باید تعیین شود. تابع هدف فوق انحراف مقادیر برآورد شده از داده های مشاهده شده را برای دو نوع داده در نظر گرفته است. عامل انحراف در ماتریس O-D حمل و نقل مشاهده شده و تخمین زده شده است ، در حالی که عامل انحراف در تعداد حجم ترافیک کامیون های مشاهده شده و تخمین زده شده است. بنابراین ، این عوامل باید برای حل مدل تعیین شوند. برای این منظور ، چندین شبیه سازی از مدل برای ترکیبات مختلف و انجام شد. این فرض منجر به شد. این ترکیب باعث
می شود که عملکرد هدف با حداقل مقدار بدست آید.
همانطور که در بالا ذکر شد و با در نظر گرفتن شرایط تحقیق و داده های موجود ، ترکیب و با 50درصد انتخاب شد. زرگری و همدانی (2006) نیز از طریق بررسی میدانی به این ضرایب دست یافتند. این مقادیر در ماتریس O-D باربری بهترین پاسخ را دارند. سرانجام ، با اختصاص ماتریس تخمین زده شده نهایی به شبکه جریان باری در پیوندهای شبکه حاصل شد. شکل 6 تناظر بین کامیون های دو محوره را که از 100 پیوند که دارای بیشترین حجم عبور هستند ، بر اساس مشاهدات و مقادیر محاسباتی به دست آمده از واگذاری بهینه ماتریس O-D حمل و نقل به شبکه ، نشان می دهد. خط نصب شده دارای ضریب همبستگی 85/0 است که نشان دهنده مناسب بودن نتایج است. شکل 7 همچنین مکاتبات یک به یک از ماتریس باربری اولیه O-D و ماتریس نهایی برای 100 جفت برتر را نشان می دهد همانطور که در نمودار نشان داده شده است. ضریب همبستگی خط تعبیه شده 89/0 است که به نظر می رسد نتیجه قابل قبولی از برآورد ماتریس باری است. پس از استفاده از مدل پیش بینی شده ، نتایج آن باید مورد بررسی قرار گیرد. در این مطالعه ، میزان ترافیک مشاهده شده و تخمین زده شده نیز باید مورد تجزیه و تحلیل قرار گیرد. پارامترهای زیادی برای این منظور وجود دارد مانند میانگین خطای درصد مطلق (MAPE) ، خطای میانگین مربعات خطا (RMSE) و خطای میانگین مطلق (MAE) که می توانند تفاوت بین مشاهدات و محاسبات را نشان دهند. علاوه بر این ، پارامتر دیگری نیز به نام GEH وجود دارد که توسط Geoffrey Havers برای اولین بار تعریف شده است. این شاخص براساس ADT توسط (Horowitz et al.، 2014) تعریف شده است به شرح زیر:
به شرطی که :
M = تخمین میزان ترافیک ADT C= تعداد ترافیک مشاهده شده ADT
یکی از مزیت های این پارامتر این است که می توان در موضوعات مربوط به پیش بینی میزان ترافیک در برنامه ریزی حمل و نقل استفاده کرد. برای مقایسه میزان ترافیک روزانه مشاهده شده و تخمین زده شده پارامتر زیر تعریف شده است:
این پارامتر برای هر لینک به طور جداگانه محاسبه می شود و نتایج آن به شرح زیر تفسیر می شود:
GEH < 5 مناسب قابل قبول ، احتمالاً خوب است
5 < GEH < 10 توجه: خطای احتمالی مدل یا داده های بد
GEH > 10 هشدار: احتمال زیاد خطای مدل یا داده های بد
شکل 6. حجم مشاهده شده از کامیون های 2 محوره در برابر خودروهای برآورد شده (وسیله نقلیه در روز)
شکل 7. ماتریس اولیه O-D در برابر موارد تخمین زده شده برای 100 جفت برتر (تن / سال)
نتایج این پارامتر برای پیوندهای شبکه و همچنین کامیون هایی با دو محوره سه ، یا بیشتر در جدول 1 و جدول 2 نمایش داده شده است.
جدول 1 : تجزیه و تحلیل عملکرد GEH برای میانگین تردد کامیون های دو محور در روز
جدول 2 : تجزیه و تحلیل عملکرد GEH برای میانگین تردد کامیون های سه محوره یا بیشتر در روز
نتایج به شرح زیر تحلیل می شوند:
همانطور که در جداول 1 و 2 مشخص شده است ، در تخمین کامیون های دو محوره در 87٪ پیوندها ، عملکرد GEH کمتر از 5 است. این شاخص برای کامیون های سه محوره 82٪ یا بیشتر است که نشان دهنده اثربخشی نتایج است.
5- نتیجه گیری
در این مقاله روشی برای برآورد ماتریس O-D باری بر اساس شمارش حجم ترافیک وسایل نقلیه تجاری در پیوندهای شبکه ارائه شده است. این روش مبتنی بر به حداقل رساندن حداقل مربعات بین ماتریس اولیه بار O-D و جریان حمل بار در پیوندها است. مشخص است که مبادله حمل و نقل بین مناطق در یک کشور رابطه مستقیمی با حمل و نقل وسایل نقلیه تجاری باری از جمله انواع کامیون (2 محوره ، 3 محوره و …) دارد. با توجه به اینکه در 1165 نقطه در ایران ، شمارنده های راهنمایی و رانندگی وجود دارد که اطلاعات را بر اساس انواع خودرو کاملاً آنلاین ، حساب می کند ، از این داده ها و اطلاعات دیگری که از نظرسنجی های دوره ای به دست می آید و به نوعی با مبادله حمل و نقل بین مناطق ارتباط دارد ، قابل استفاده است. ماتریس حمل و نقل O-D را می توان در فواصل کمتر از یک سال نیز تخمین زد. برای حل این مدل ، از الگوریتم متا اکتشافی شبیه سازی شده تبرید استفاده شده است. اگرچه می توان از الگوریتم های دیگر اکتشافی دیگر برای مقایسه نتایج در مطالعات آینده استفاده کرد ، اما نتایج به دست آمده از حل مدل با الگوریتم شبیه سازی تبرید نشان می دهد که تا حد زیادی نتایج قابل قبول است. این مسئله با مقایسه ضریب همبستگی بردار جریان بار مشاهده شده در لینکهای شبکه و جریان بار محاسباتی بدست آمده از راه حل مدل و همچنین ضریب همبستگی ماتریس اولیه به دست آمده از بررسی و تخمین ماتریس بار OD به دست آمده از راه حل مدل تأیید شده است.

